Replication เป็นเทคโนโลยีพื้นฐานสำหรับเซิร์ฟเวอร์ฐานข้อมูล เนื่องจากการหยุดทำงาน หรือข้อมูลสูญหายอาจส่งผลให้ลดความสามารถในการเข้าถึง ลดประสิทธิภาพการทำงาน และความเชื่อมั่นของผลิตภัณฑ์
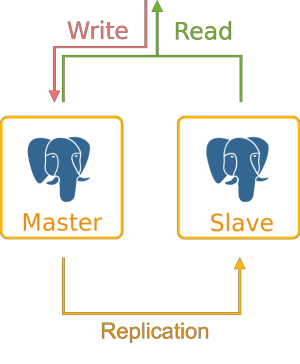
การใช้การจำลองข้อมูลจากเซิร์ฟเวอร์หลัก (master) ไปยัง standby เซิร์ฟเวอร์ (slaves) อย่างน้อยหนึ่งตัวจะลดความเป็นไปได้ที่ข้อมูลจะสูญหายได้ ด้วย PostgreSQL คุณสามารถสร้างคลัสเตอร์ฐานข้อมูลของ Master-Slave topology ด้วย standby เซิร์ฟเวอร์ ตั้งแต่หนึ่งตัวขึ้นไป

การใช้ WAL (Write-Ahead Logging) เป็นวิธีการจำลองแบบที่เร็วที่สุดพร้อมประสิทธิภาพที่ยอดเยี่ยมซึ่งเรียกว่า asynchronous replication ในกรณีนี้เซิร์ฟเวอร์ฐานข้อมูลตัวหลัก (Master) จะทำงานในโหมดการเก็บข้อมูลถาวร เพียงแค่เขียนไฟล์ WAL ไปยังหน่วยจัดเก็บข้อมูล (Storage) และกระจายข้อมูลไปยังเซิร์ฟเวอร์ฐานข้อมูล Standby (slave) ที่ทำงานในโหมด recovery ไฟล์เหล่านี้จะถูกโอนไปยังฐานข้อมูล Standby ทันทีหลังจากการเขียนเสร็จสิ้น
ดังนั้นเรามาดูว่าพารามิเตอร์การกำหนดค่าหลักถูกตั้งค่าเพื่อกำหนดค่าคลัสเตอร์ฐานข้อมูล PostgreSQL ของ Master-Slave topology ที่มีความพร้อมใช้งานสูงโดยการตั้งค่าการจำลองแบบ hot_ standby (หรือสตรีมมิ่ง) ให้กับ slaves อย่างน้อยหนึ่งรายการที่สามารถคิวรี่เป็นฐานข้อมูลแบบอ่านได้อย่างเดียว
เนื่องจาก PostgreSQL เปลี่ยนการกำหนดค่าในทุกรุ่นที่มาใหม่บทความนี้จะใช้ได้กับเวอร์ชัน 13.2 ซึ่งเป็นเวอร์ชันล่าสุดในขณะนี้
สร้าง Environment
ในหน้า Dashbard ของ Ruk-Com Cloud จะมี PostgresSQL ที่มาพร้อมกับฟีเจอร์ Auto-Clustering สามารถเรียกได้จากตัวช่วยสร้าง Environment Topology wizard (ปุ่ม NEW ENVIRONMENT) เมื่อเปิดขึ้นมาแล้วให้เลือกซอร์ฟแวร์ฐานข้อมูลเป็น PostgresSQL 12.3 และเปิดสวิตช์ Auto-Clustering
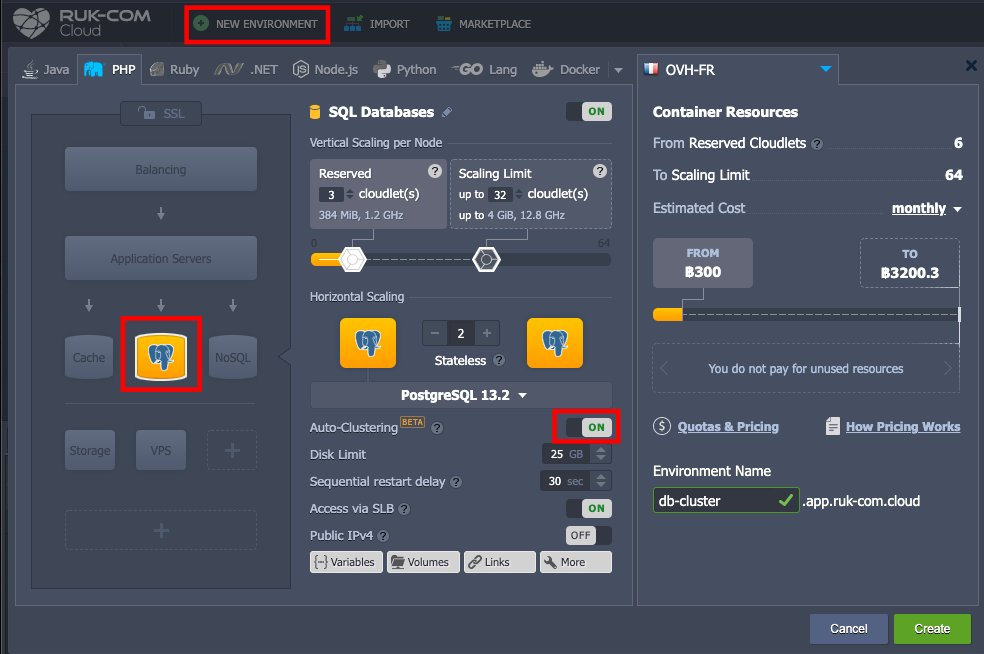
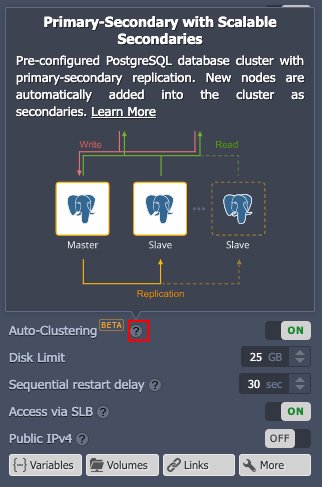
หากต้องการข้อมูลเพิ่มเติมสามารถวางเมาส์เหนือเครื่องหมายคำแนะนำเครื่องมือ จะมีคำแนะนำเกี่ยวกับ Topology ขึ้นมา
การตั้งค่า Master PostgreSQL
มาดูพารามิเตอร์การกำหนดค่า master node ที่ใช้ในการทำ auto-clustering
1. ค้นหา Environment ของฐานข้อมูลตัว master ในลิสรายการ Environment คลิกปุ่ม Config ของโหนด PostgreSQL ตัว Master
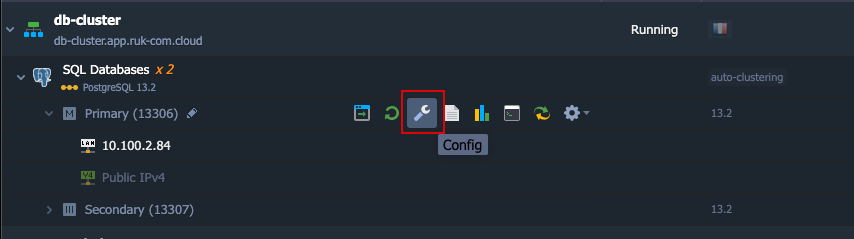
2. เปิดไดเร็กทอรี conf และไปที่ไฟล์ postgresql.conf
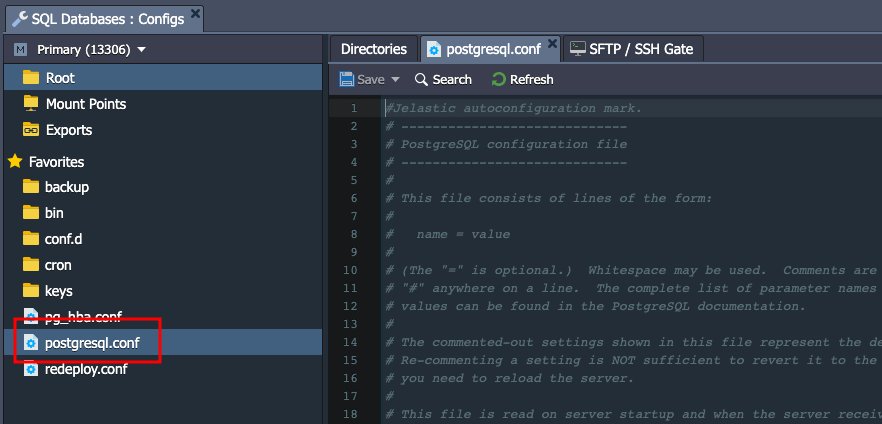
การตั้งค่าต่อไปนี้จะเกี่ยวข้องกับ WAL สามารถเปลี่ยนแปลงได้ตามความต้องการ:
wal_level = hot_standby
max_wal_senders = 10
archive_mode = on
archive_command = 'cd .'โดยที่:
- พารามิเตอร์ wal_level กำหนดปริมาณข้อมูลที่เขียนไปยัง WAL มีสามค่าที่มีความเป็นไปได้:
– minimal – เหลือเพียงข้อมูลที่จำเป็นในการกู้คืนจากความล้มเหลวหรือการปิดระบบฉุกเฉิน
– replica – ค่า default ซึ่งเขียนข้อมูลเพียงพอที่จะรองรับการเก็บถาวรและการจำลองแบบ WAL รวมถึงการรันคิวรีแบบอ่านอย่างเดียวบน standby เซิร์ฟเวอร์ ในรุ่นก่อนหน้านี้ถึงรุ่น 9.6 ค่าที่เก็บถาวรและค่า hot_standby จะได้รับอนุญาตสำหรับพารามิเตอร์นี้ ในรุ่นหลังจากนี้จะเป็นที่ยอมรับในการใช้งานได้ แต่เป็นการแมปกับแบบจำลอง
– logical – ค่าจะเพิ่มข้อมูลที่จำเป็นเพื่อสนับสนุนการ decoding ลอจิกไปยังระดับการบันทึกแบบจำลอง - max_wal_senders กำหนดจำนวนสูงสุดของกระบวนการถ่ายโอน WAL ที่รันพร้อมกัน
- archive_mode อนุญาตให้เก็บ WAL พร้อมกับพารามิเตอร์ wal_level (ค่าทั้งหมดเปิดใช้งานการเก็บถาวรยกเว้นค่าที่ต่ำสุด)- archive_command คำสั่ง local shell ที่จะดำเนินการเพื่อเก็บเซ็กเมนต์ WAL ที่เสร็จสมบูรณ์อย่างถาวร โดยค่าเริ่มต้นจะไม่มีการทำอะไรโดยการเรียกใช้งาน ‘cd’ นั่นหมายความว่าการเก็บถาวรถูกปิดใช้งาน คุณอาจลองเปลี่ยนสิ่งต่อไปนี้เพื่อคัดลอก archive ไฟล์ของ WAL ไปยังไดเร็กทอรีปลายทางที่คุณต้องการ (เช่น /tmp/mydata):
archive_command = 'test ! -f /var/lib/pgsql/data/pg_wal/%f && cp %p /tmp/mydata/%f'หลังจากตั้งค่าเสร็จแล้วกดปุ่ม Save ด้านบน

- เปิดไฟล์ config pg_hba.conf อนุญาตให้เชื่อมต่อฐานข้อมูล Standby (slave) โดยระบุพารามิเตอร์ต่อไปนี้:
host replication all {standby_IP_address}/32 trust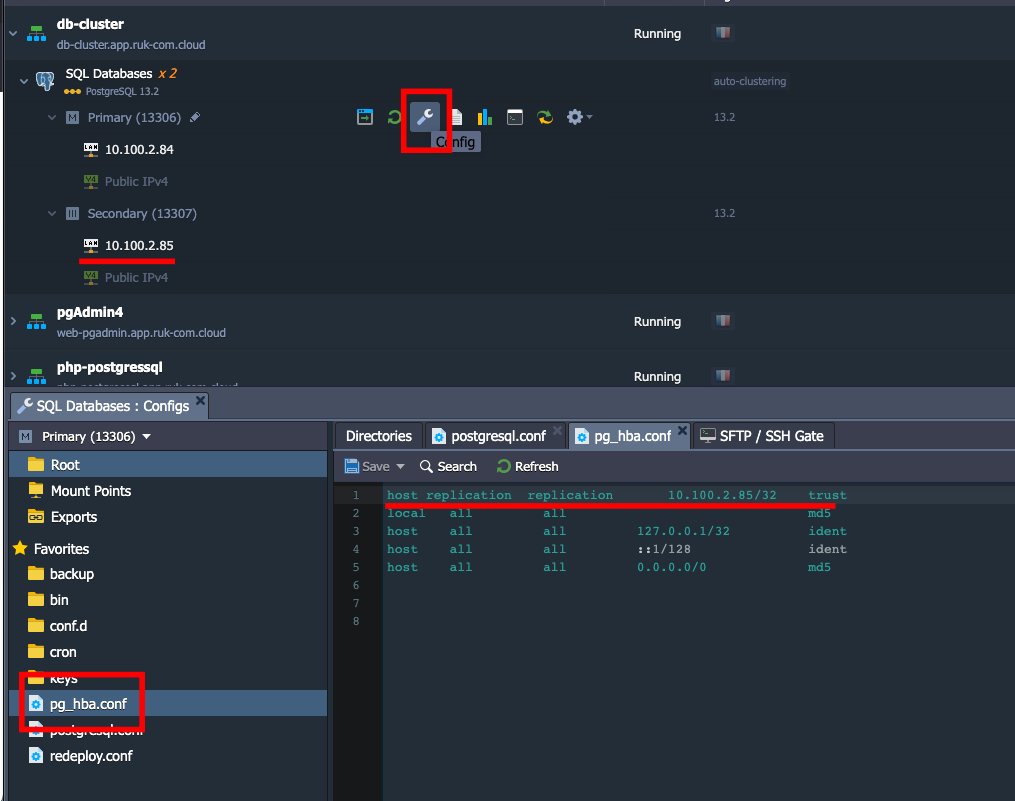
เสร็จสิ้นการกำหนดค่าสำหรับโหนด master มาดำเนินการต่อในการกำหนดค่าสำหรับโหนด Standby (slave)
กำหนดค่าโหนด Standby (slave)
มาตรวจสอบไฟล์การกำหนดค่าที่โหนด Slave มีเพียงสามตัวเลือกที่แยกความแตกต่างของ slave ออกจาก master:
1. เปิดไฟล์ postgresql.conf ค้นหาส่วน Standby Servers ดังที่เห็นเซิร์ฟเวอร์นี้ จะเป็นโหมด Standby อยู่ เพราะว่าพารามิเตอร์ hot_standby นั้นมีสถานะเป็น on ไม่เหมือนกับ master node ที่พารามิเตอร์นี้ถูกคอมเมนต์ไว้
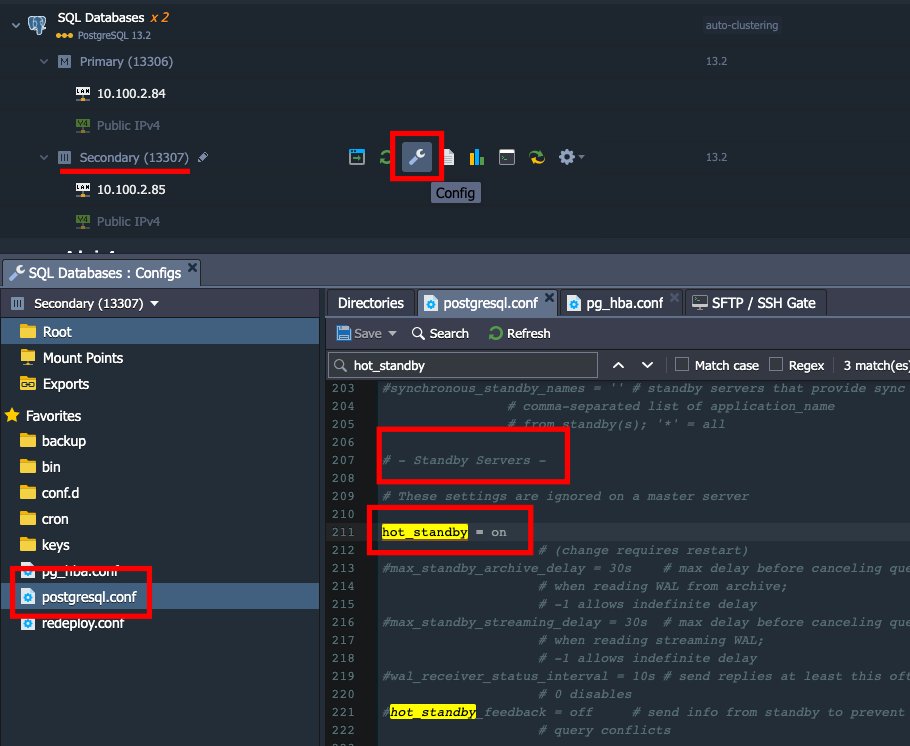
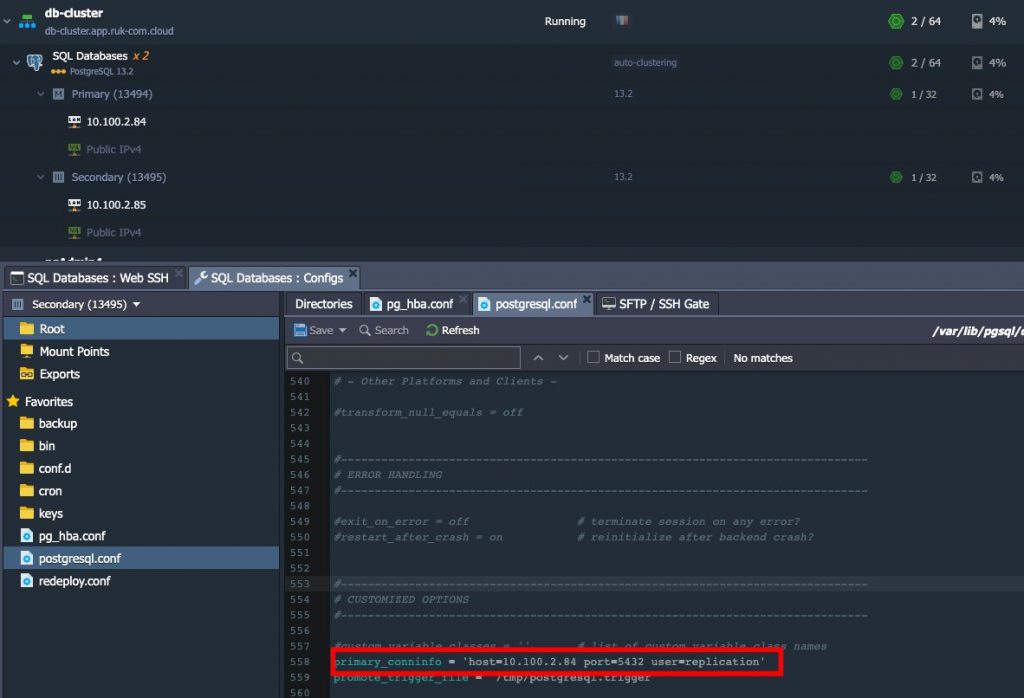
2. เลื่อนลงไปที่ท้ายไฟล์ config มีพารามิเตอร์ primary_conninfo ที่ระบุการเชื่อมต่อซึ่ง standby เซิร์ฟเวอร์จะใช้เพื่อเชื่อมต่อกับเซิร์ฟเวอร์ที่เป็นผู้ส่ง สตริงการเชื่อมต่อต้องระบุชื่อโฮสต์ (หรือ address) ของเซิร์ฟเวอร์ที่ส่งรวมทั้งหมายเลขพอร์ต นอกจากนี้ยังมีชื่อผู้ใช้ที่สอดคล้องกันพร้อมสิทธิ์ที่เหมาะสมบนเซิร์ฟเวอร์ที่ส่ง ต้องระบุรหัสผ่านใน primary_conninfo หรือในไฟล์ ~/.pgpass แยกต่างหากบนเซิร์ฟเวอร์สำรองหากผู้ส่งต้องการการยืนยันตัวตนด้วยรหัสผ่าน
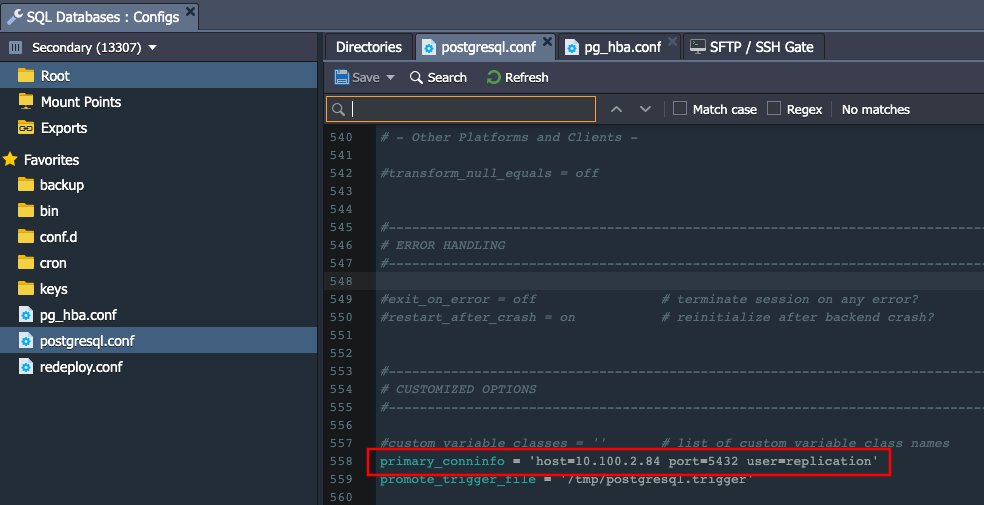
3. ตัวเลือกสุดท้ายที่ทำให้เซิร์ฟเวอร์ฐานข้อมูลเป็น slave คือความพร้อมใช้งานของไฟล์ standby.signal ซึ่งบ่งชี้ว่าเซิร์ฟเวอร์ควรเริ่มการทำงานแบบ hot standby ไฟล์ต้องอยู่ในไดเร็กทอรี PostgreSQL data และอาจว่างเปล่าหรือมีข้อมูลใด ๆ อยู่ เมื่อ slave ได้รับการเลื่อนขึ้นเป็น master ไฟล์นี้จะถูกลบไป
หมายเหตุ :
โปรดทราบว่าตัวเลือกส่วนใหญ่ที่มีการเปลี่ยนแปลงจำเป็นต้องรีสตาร์ทเซิร์ฟเวอร์ สามารถทำได้สองวิธี:
1. จากแดชบอร์ดคุณสามารถรีสตาร์ทโหนดใดโหนดหนึ่งหรือทั้งสองโหนดก็ได้

2. ทำผ่าน command line interface ผ่านไปยัง Web SSH client โดยคลิกที่ปุ่ม Web SSH ที่โหนดที่ต้องการ เช่น slave
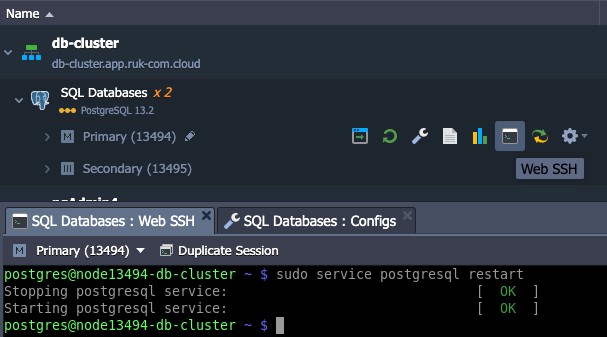
และป้อนคำสั่งเพื่อรีสตาร์ทเซิร์ฟเวอร์ฐานข้อมูล:
sudo service postgresql restartตรวจสอบการ Replication
1. เปิดพาเนล phpPgAdmin สำหรับฐานข้อมูล master โดยคลิกปุ่ม Open in Browser ที่อยู่ข้าง ๆ
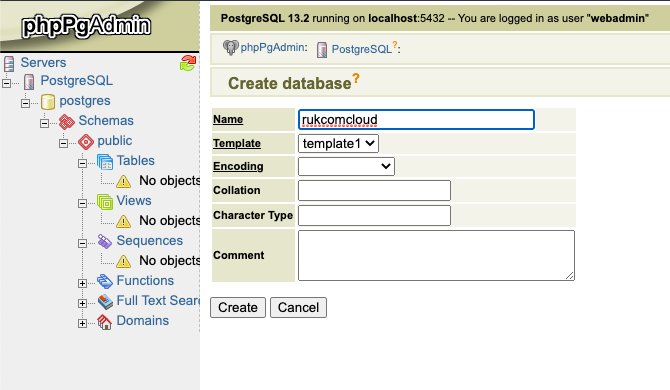
2. ล็อกอินด้วยข้อมูลรับรองฐานข้อมูลที่ได้รับทางอีเมลก่อนหน้านี้และสร้างฐานข้อมูลใหม่
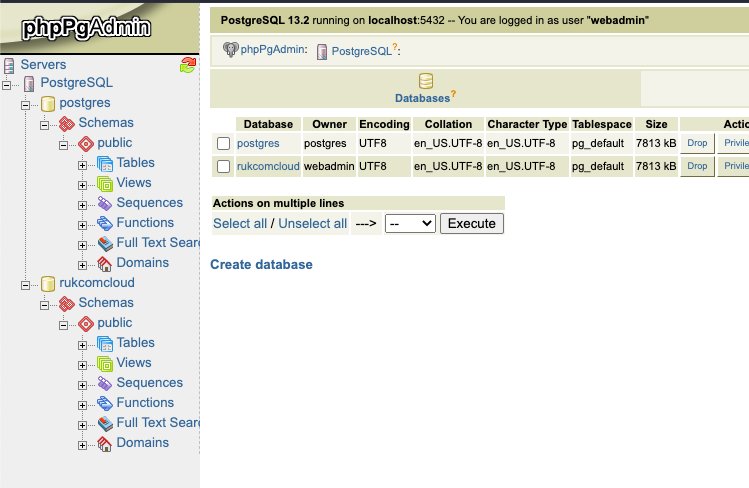
3. จากนั้นคุณควรเปิดพาเนลแอดมินของเซิร์ฟเวอร์ฐานข้อมูลโหนด standby (ในลักษณะเดียวกับ master) และตรวจสอบว่าฐานข้อมูลใหม่ถูกสร้างขึ้นสำเร็จหรือไม่
Failover Scenario
PostgreSQL ไม่มี native automatic failover scenario สำหรับคลัสเตอร์ฐานข้อมูลในทางกลับกันเนื่องจากมีโซลูชัน third-party มากมายที่คุณสามารถใช้เพื่อปรับใช้เพื่อให้แน่ใจว่าระบบของคุณมีความพร้อมใช้งานสูง ในขณะเดียวกันคุณอาจสร้างโซลูชันของคุณเองเพื่อหยุดความล้มเหลวของคลัสเตอร์ฐานข้อมูล สถานการณ์หลายอย่างของความล้มเหลวของคลัสเตอร์เป็นไปได้ในชีวิตจริง ในที่นี้เราจะพิจารณาขั้นตอนการทำงานที่พบบ่อยที่สุดเพียงขั้นตอนเดียวเท่านั้นที่สามารถช่วยคุณในการทำ automate failover scenario
Topology เริ่มต้นประกอบด้วยสองโหนด:
เมื่อ master node ล้มเหลว slave node จะต้องเลื่อนระดับเป็นโหนด master ใหม่ สามารถทำได้ด้วยยูทิลิตี้ pg_ctl ซึ่งใช้ในการเตรียมใช้งานเริ่มต้นหยุดหรือควบคุมเซิร์ฟเวอร์ PostgreSQL ในการล็อกอินเข้าสู่เซิร์ฟเวอร์ standby ผ่าน Web SSH และใช้คำสั่งดังนี้:
/usr/pgsql-13/bin/pg_ctl promote -D /var/lib/pgsql/dataโดยที่ /var/lib/pgsql/data คือไดเร็กทอรีข้อมูลของฐานข้อมูล
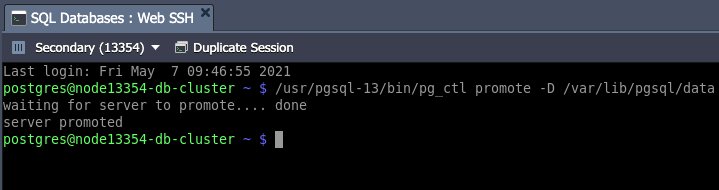
เมื่อเลื่อนขั้นฐานข้อมูล slave เป็น master แล้ว คุณควรเปลี่ยนสตริงการเชื่อมต่อแอปพลิเคชัน เปลี่ยน entry point ของคลัสเตอร์ฐานข้อมูลเป็นชื่อโฮสต์หรือ IP address ใหม่
กระบวนการ Failover สามารถอาศัยการใช้งาน pg_isready utility ที่ตรวจสอบการเชื่อมต่อกับฐานข้อมูล PostgreSQL ได้
คุณสามารถสร้างสคริปต์ง่าย ๆ ที่ตรวจสอบความพร้อมใช้งานของเซิร์ฟเวอร์ฐานข้อมูล master และส่งเสริมการ standby ในกรณีที่ master เกิดความล้มเหลว รันสคริปต์ผ่าน link # crontab ที่ slave node ด้วยช่วงเวลาที่เหมาะสม สคริปต์อาจมีลักษณะดังนี้ เรียกว่า failover.sh:
#!/bin/bash
master="10.100.2.84"
slave="10.100.2.85"
status=$(/usr/pgsql-13/bin/pg_isready -d postgres -h $master)
response="$master:5432 - no response"
if [ "$status" == "$response" ]
then
/usr/pgsql-13/bin/pg_ctl promote -D /var/lib/pgsql/data
echo "Slave promoted to new Master. Change your app connection string to new Master address $slave"
else
echo "Master is alive. Nothing to do."
fiเมื่อสคริปต์ถูก trigger การเลื่อนขั้น slave เป็น master ผลลัพธ์ของสคริปต์ควรมีลักษณะดังนี้:
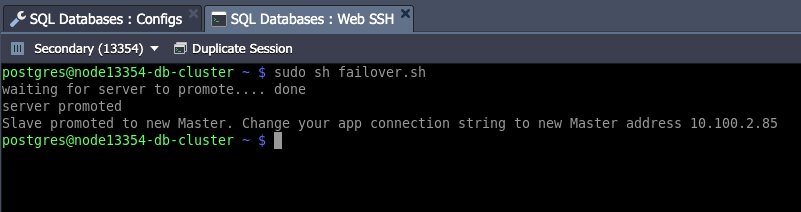
ตอนนี้ฐานข้อมูลของคุณกลับมาใช้งานได้แล้วและพร้อมที่จะจัดการ read/write ตาม master address ใหม่
Cluster Restoration
ด้วย master address ใหม่คุณสามารถหลีกเลี่ยงการปรับแต่งสตริงการเชื่อมต่อแอปพลิเคชันของคุณโดยเปลี่ยน ip address ของฐานข้อมูล master ได้อย่างง่ายดาย ในการดำเนินการนี้คุณต้องวาง load balancer ที่ด้านหน้าของคลัสเตอร์ที่จะตรวจสอบสถานะของส่วนประกอบและกำหนดเส้นทางการรับส่งข้อมูลไปยัง master ปัจจุบัน แต่สิ่งนี้อยู่นอกขอบเขตของเอกสารนี้ เราจะสาธิตวิธีการคืนค่าดั้งเดิมของ cluster topology ดังนั้นจึงไม่จำเป็นต้องมีการเปลี่ยนแปลงใด ๆ ที่ส่วน frontend
อีกเหตุผลหนึ่งที่ควรกู้คืน topology เกี่ยวข้องกับการรับรองความสามารถในการปรับสเกลของคลัสเตอร์ Topology แบบดั้งเดิมเท่านั้นที่สามารถปรับสเกลเข้า / ออกในแนวนอนได้
มาดูวิธีการกู้คืนคลัสเตอร์ฐานข้อมูล PostgreSQL หลังจากที่ master เก่าถูกละทิ้งออกจากคลัสเตอร์และ slave เดิมได้รับการเลื่อนขั้นเป็น master
ดังนั้นงานคือ: master ที่ถูกละทิ้งควรกลายเป็น master ที่แท้จริงและ master ในปัจจุบัน (ที่เลื่อนขั้นมาจาก slave) ควรกลายเป็น slave ที่แท้จริงแทน
ข้อมูลเบื้องต้นคือ:
– ข้อมูลเริ่มต้นคือคลัสเตอร์ฐานข้อมูลประกอบด้วยโหนด master สองโหนด (IP: 10.2.100.84) และ slave (IP: 10.2.100.85)
– Master node หยุดทำงานและฐานข้อมูลหลักหยุดทำงาน
– ฐานข้อมูล Standby ได้รับการเลื่อนระดับเป็นตัว master
– ตอนนี้ slave ยังคง reads/writes
– master node เดิมได้รับการแก้ไขแล้ว และพร้อมที่จะแนะนำให้รู้จักกับการจำลองแบบเป็นหลัก
ทำตามขั้นตอนต่อไปนี้เพื่อรับคลัสเตอร์ของโทโพโลยีเริ่มต้น:
- เพื่อจำลองการพังของฐานข้อมูล จะทำการลบข้อมูลออก ให้เข้าไป web SSH ที่ master node และ ป้อนคำสั่ง:
rm -rf /var/lib/pgsql/data/*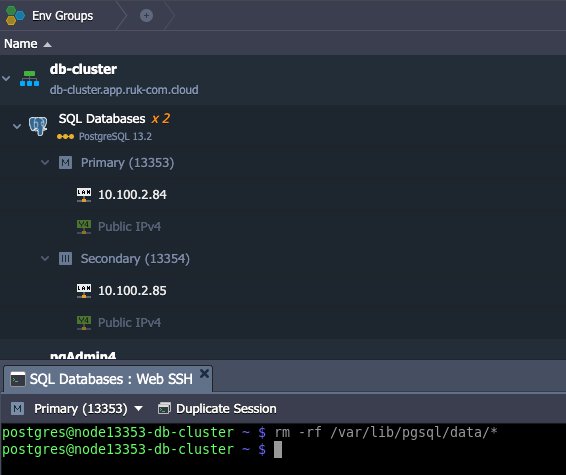
2. เพิ่ม master IP address เดิม 10.100.2.84 ไปยัง pg_hba.conf ที่ master node ปัจจุบัน (ตอนนี้เป็นโหนด secondary):
host replication replication 10.100.2.84/32 trust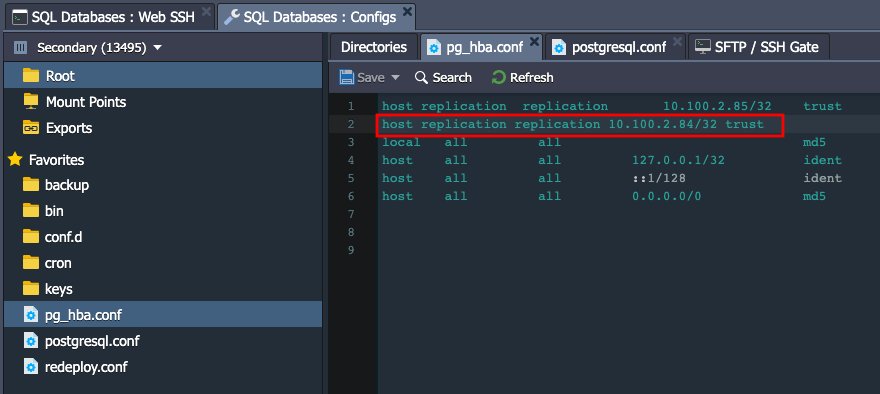
จะทำให้ โหนด master เดิม สามารถเข้าถึง master ปัจจุบันได้ จากนั้นรีสตาร์ทฐานข้อมูลหลักในปัจจุบัน (ตอนนี้เป็นโหนด secondary) เพื่อทำการเปลี่ยนแปลงค่า
sudo service postgresql restart3. ไปยัง master node เดิม ผ่านทาง Web SSH และ ป้อนคำสั่ง:
pg_basebackup -U replication -h 10.100.2.85 -D /var/lib/pgsql/data -Fp -Xs -P -R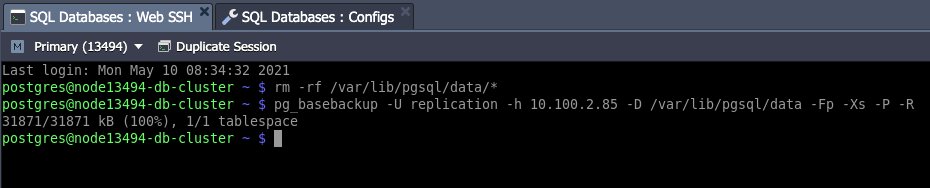
โดยที่:
- link # pg_basebackup – ใช้เพื่อสำรองข้อมูลพื้นฐานของคลัสเตอร์ฐานข้อมูล PostgreSQL ที่รันอยู่
- 10.100.2.85 – IP address ของ master node ปัจจุบัน
- /var/lib/pgsql/data – ไดเร็กทอรีข้อมูล PostgreSQL
4. ตรวจสอบให้แน่ใจว่า ip address ในโฮสต์พารามิเตอร์ที่อธิบายไว้ในข้อ #2 ของการ link #Configuring Standby มี ip address ที่เหมาะสมกับ master เดิม
5. สร้างไฟล์ standby.signal ที่ master ปัจจุบัน:
touch /var/lib/pgsql/data/standby.signal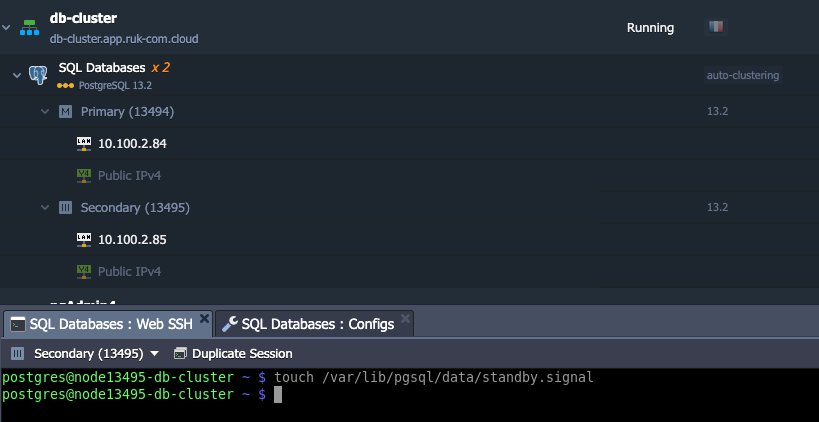
และรีสตาร์ทโหนดเพื่อรับฐานข้อมูล slave ใหม่:
sudo service postgresql restartลบไฟล์ standby.signal ที่ master เดิม:
rm /var/lib/pgsql/data/standby.signal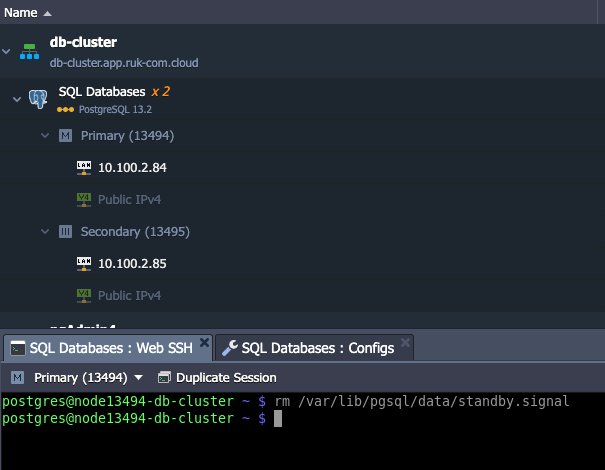
และรีสตาร์ทโหนดเพื่อรับฐานข้อมูล master ใหม่
sudo service postgresql restart6. สุดท้ายเพื่อให้ได้สถานะการกู้คืนที่สอดคล้องกันสำหรับทั้งฐานข้อมูลหลักและฐานข้อมูล standby จำเป็นต้องมีการรีสตาร์ทครั้งสุดท้ายซึ่งสามารถทำได้ผ่านแดชบอร์ดดังนี้:
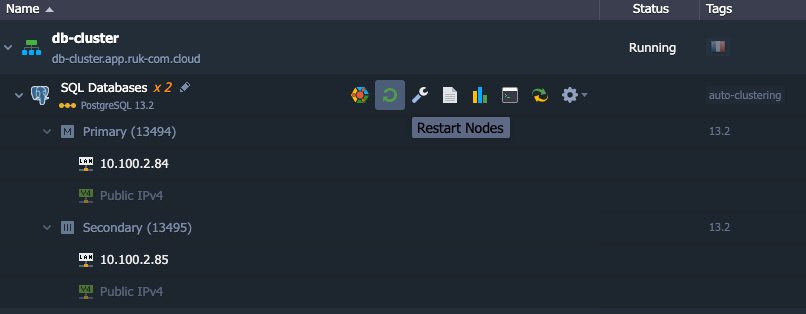
เมื่อกระบวนการรีสตาร์ทเสร็จสิ้นคลัสเตอร์จะกลับมาที่โทโพโลยีดั้งเดิมและอาจถูกปรับสเกลในแนวนอน

