Ruk-Com Cloud จัดเตรียมคลัสเตอร์อัตโนมัติสำหรับ MongoDB stack ซึ่งช่วยให้คุณสร้าง replica set ที่เชื่อถือได้สำหรับฐานข้อมูลของคุณด้วยการคลิกเพียงครั้งเดียว วิธีแก้ที่นำไปใช้มีประโยชน์มากมาย:
- ความซ้ำซ้อนและความพร้อมใช้งานของข้อมูลสูง – ทำสำเนาข้อมูลหลาย ๆ ชุดบนเซิร์ฟเวอร์ฐานข้อมูลที่แตกต่างกันช่วยให้สามารถรับความผิดพลาดในระดับสูงต่อการสูญหายของข้อมูลได้
- ความสามารถในการปรับสเกลและการค้นหาอัตโนมัติ – โหนดใหม่ที่เพิ่มเข้ามาระหว่างการ horizontal scaling จะเชื่อมต่อกับคลัสเตอร์โดยจะใช้การปรับเปลี่ยนที่จำเป็นทั้งหมดโดยอัตโนมัติ
- การล้มเหลวอัตโนมัติ – โหนดฐานข้อมูลที่ไม่สามารถใช้งานได้ชั่วคราวหรือมีเวลาแฝงสูงจะถูกแยกออกจากคลัสเตอร์โดยอัตโนมัติและจะเพิ่มเข้าไปใหม่เมื่อการเชื่อมต่อกลับคืนมา

ประโยชน์ทั้งหมดนี้สามารถทำได้เพียงไม่กี่คลิกภายใน topology wizard สำรวจขั้นตอนด้านล่างเพื่อเปิดใช้งานการทำคลัสเตอร์อัตโนมัติสำหรับฐานข้อมูล MongoDB ของคุณใน Ruk-Com PaaS
ข้อมูลจำเพาะของ MongoDB Auto-Clustering
Link # replica set คือกลุ่มของ MongoDB instance อย่างน้อย 3 instance ที่เก็บรักษาข้อมูลเดียวกัน มีโหนดหนึ่งของชุดถือเป็นโหนดหลักและรับผิดชอบการดำเนินการเขียนทั้งหมด บันทึกการเปลี่ยนแปลงทั้งหมดใน oplog เพื่อให้โหนดที่เหลือ (ลำดับที่สอง) สามารถสะท้อนถึงข้อมูลหลักได้อย่างถูกต้อง หากตัวหลักไม่พร้อมใช้งานรายการใหม่จะถูกเลือกโดยอัตโนมัติจากตำแหน่งรองที่ใช้งานอยู่หลังจากมีการล่าช้าไปสักครู่หนึ่ง
ค่าเริ่มต้นสำหรับการ settings ของคลัสเตอร์ที่กำหนดค่าโดยอัตโนมัติมีดังต่อไปนี้:
- “chainingAllowed” : true – อนุญาตให้สมาชิกรองสามารถจำลองแบบจากลำดับรองอื่น ๆ ได้
- “heartbeatIntervalMillis” : 2000 – ความถี่ในหน่วยมิลลิวินาทีสำหรับการเต้นของหัวใจ
- “heartbeatTimeoutSecs” : 10 – การหมดเวลาเป็นหน่วยวินาทีที่สมาชิกตั้งค่าแบบจำลองรอให้การเต้นของหัวใจสำเร็จก่อนที่จะทำเครื่องหมายโหนดที่เหมาะสมว่าไม่สามารถเข้าถึงได้
- “electionTimeoutMillis” : 10000 – การหมดเวลาเป็นมิลลิวินาทีสำหรับการตรวจสอบว่าสมาชิกหลักไม่สามารถเข้าถึงได้หรือไม่
- “catchUpTimeoutMillis” : -1 – การหมดเวลาเป็นมิลลิวินาที (-1 สำหรับเวลาที่ไม่มีที่สิ้นสุด) สำหรับตัวหลักที่เพิ่งได้รับการคัดเลือกเพื่อติดต่อกับสมาชิกที่มีการเขียนล่าสุด
- “catchUpTakeoverDelayMillis” : 30000 – การหมดเวลาเป็นมิลลิวินาทีของโหนดรองซึ่งอยู่ข้างหน้าโหนดหลักในปัจจุบันให้การติดตามก่อนที่จะเริ่มการคัดเลือกเพื่อเป็นโหนดหลักใหม่
เคล็ดลับ :
หากจำเป็นคุณสามารถกำหนดค่าการตั้งค่าเหล่านี้ใหม่ได้ด้วยตนเองหลังจากการติดตั้งคลัสเตอร์โดยใช้คำสั่ง rs.reconfig() ตรวจสอบส่วนด้านล่างเพื่อเรียนรู้วิธีเชื่อมต่อกับคลัสเตอร์ MongoDB ของคุณผ่าน SSH และรันคำสั่งที่จำเป็น
จุดสำคัญอีกประการหนึ่งคือความปลอดภัยและการป้องกันจากการเข้าถึงที่ไม่ต้องการ ด้วยเหตุนี้ authentication เป็นกระบวนการประกันความปลอดภัยที่สำคัญ ซึ่งบังคับให้สมาชิกของแต่ละชุดจำลองระบุตัวตนระหว่างการสื่อสารภายในโดยใช้คีย์ไฟล์การพิสูจน์ตัวตนพิเศษ แพลตฟอร์มจะใช้การกำหนดค่าที่จำเป็นโดยอัตโนมัติ (ใน /etc/mongod.conf) และสร้างคีย์ (อยู่ที่ /home/jelastic/mongodb.key) ในระหว่างการกำหนดค่าคลัสเตอร์ นอกจากนี้เพื่อให้แน่ใจว่ามีความสอดคล้องกัน ไฟล์จะถูกเพิ่มลงในไฟล์ link # redeploy.conf เพื่อให้ไฟล์ยังคงอยู่ตลอดการดำเนินการตลอดอายุการใช้งานคอนเทนเนอร์
MongoDB ใช้เครื่องมือจัดเก็บข้อมูล WiredTiger ตามค่าเริ่มต้น ช่วยให้มั่นใจได้ถึงประสิทธิภาพที่สูง (เนื่องจากอัลกอริทึม non-locking) และการใช้ต้นทุน / ทรัพยากรที่มีประสิทธิภาพ ตัวเลือกเริ่มต้นสำหรับ WiredTiger ได้รับการปรับให้เหมาะกับการรัน mongod instance เดียวต่อเซิร์ฟเวอร์ซึ่งเหมาะสำหรับคอนเทนเนอร์ Ruk-Com PaaS ,MongoDB ใช้ทั้งแคชภายใน WiredTiger และแคชของ filesystem ขนาดแคชภายในคือ 50% ของ RAM ทั้งหมดลบ 1 GB (แต่ไม่น้อยกว่า 256 MB) ในขณะที่แคชของ filesystem ทำงานในหน่วยความจำว่างที่ไม่ได้ใช้โดย WiredTiger หรือกระบวนการอื่น ๆ สำหรับข้อมูลเพิ่มเติมเกี่ยวกับ WiredTiger configs โปรดดูเอกสาร MongoDB อย่างเป็นทางการ
อีกหนึ่งคุณลักษณะที่เป็นเอกลักษณ์ของ MongoDB auto-cluster คือการตรวจหาโหนดใหม่ที่เพิ่มเข้ามาโดยอัตโนมัติผ่าน horizontal scaling และการรวมไว้ในชุดการจำลองโดยไม่ต้องดำเนินการใด ๆ ด้วย
ตนเอง ในทำนองเดียวกันโหนดจะถูกแยกออกจากคลัสเตอร์ในขณะที่ขยายสเกล
เปิดใช้งานการทำคลัสเตอร์อัตโนมัติสำหรับฐานข้อมูล
กระบวนการทั้งหมดของการสร้างคลัสเตอร์อัตโนมัติของ MongoDB สามารถทำได้ในไม่กี่คลิก
1. เปิด topology wizard ด้วยปุ่ม New Environment ที่มุมบนซ้ายของแดชบอร์ดเลือกฐานข้อมูล MongoDB และเปิดใช้งาน Auto-Clustering ผ่านตัวสวิตซ์สลับที่เหมาะสม
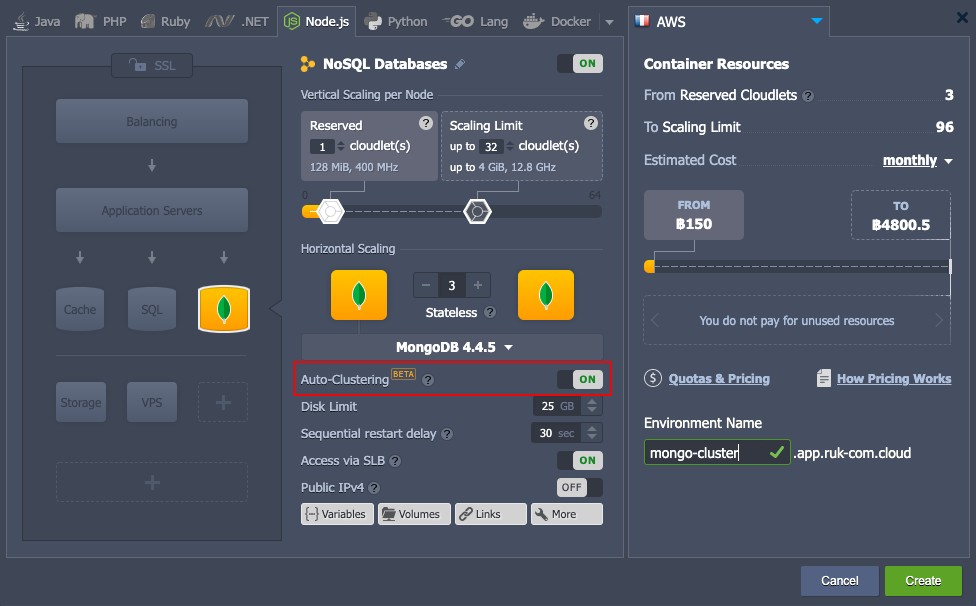
เคล็ดลับ :
ข้อมูลโทโพโลยีบางส่วนของคลัสเตอร์ MongoDB มีดังต่อไปนี้:
- รองรับการทำคลัสเตอร์อัตโนมัติตั้งแต่เวอร์ชัน 4.x.x
- แนะนำให้ใช้ RAM 4 GiB (32 cloudlets) เพื่อการทำงานที่เหมาะสมของโหนดชุดจำลอง ตามค่าเริ่มต้นจำนวน cloudlets เหล่านี้จะถูกเพิ่มเป็นลิมิตการปรับสเกลแบบไดนามิก ดังนั้น you won’t be charged unless resources are actually consumed
- จำนวนโหนดขั้นต่ำที่จำเป็นสำหรับ MongoDB auto-cluster คือ 3
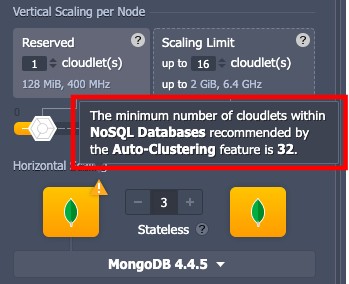
- กำหนดค่าพารามิเตอร์อื่น ๆ ตามความต้องการของคุณ (link # public IPs, link # region ฯลฯ ) แล้วคลิก Create
2. รอสักครู่เพื่อให้แพลตฟอร์มกำหนดค่าคลัสเตอร์ให้คุณ
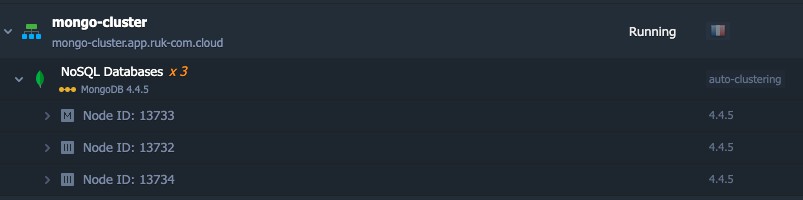
3. หลังจากติดตั้งสำเร็จคุณจะได้รับอีเมลเกี่ยวกับการกำหนดค่าชุดข้อมูลจำลองที่ประสบความสำเร็จ:
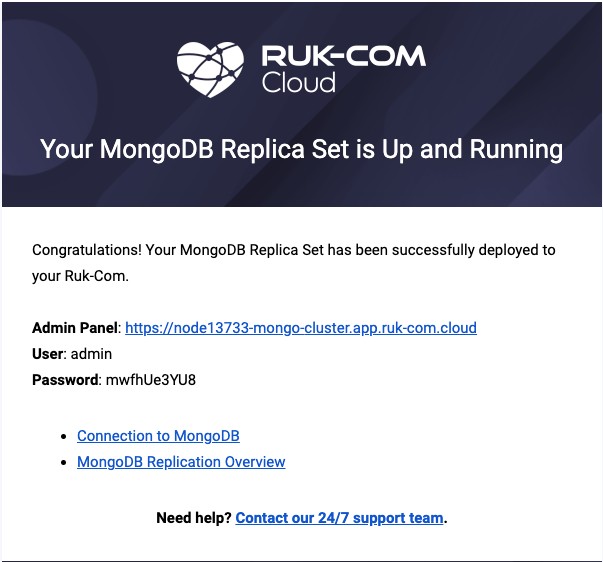
คุณสามารถใช้ข้อมูลรับรองเหล่านี้เพื่อเข้าถึงแอดมินพาเนลหรือเพื่อสร้างการเชื่อมต่อจากแอปพลิเคชันของคุณไปยังโหนดหลักของชุดข้อมูลจำลอง
เคล็ดลับ :
ตามที่กล่าวไว้โหนดรองใด ๆ อาจกลายเป็นโหนดหลักในกรณีที่เกิดการล้มเหลว การคัดเลือกอีกครั้งจะเกิดขึ้นหากคลัสเตอร์เริ่มต้นใหม่ดั งนั้นจึงมีความเป็นไปได้ค่อนข้างมากที่โหนดหลักใหม่จะเกิดขึ้น ดังนั้นสตริงการเชื่อมต่อแอปพลิเคชันจึงกลายเป็นไม่ถูกต้อง เพื่อหลีกเลี่ยงปัญหาเหล่านี้สตริงการเชื่อมต่อควรมีชื่อโฮสต์ของสมาชิกชุดการจำลองทั้งหมด ชื่อชุดแบบจำลองและ read preferences จำเป็น เพื่อยกเลิกการโหลดโหนดหลักเพื่อจัดการการอ่านหรือเพื่อให้แน่ใจว่าคลัสเตอร์มีความพร้อมใช้งานสูงและเกิดความล้มเหลว
นี่คือตัวอย่างสตริงการเชื่อมต่อในกรณีของแอปพลิเคชัน node.js:
client = new MongoClient(
"mongodb://admin:[email protected]:27017,
node254968-mongo-cluster.jelastic.com:27017,
node254969-mongo-cluster.jelastic.com:27017/admin",
{
useUnifiedTopology: true,
readPreference:'primaryPreferred',
replicaSet:'rs0'
}
);โดยที่ :
- useUnifiedTopology: true – บังคับให้ mongodb ใช้เครื่องมือค้นหาและตรวจสอบเซิร์ฟเวอร์ใหม่
- readPreference:’primaryPreferred’ – ส่วนใหญ่ดำเนินการอ่านจากตัวหลัก แต่ถ้าไม่พร้อมใช้งานการดำเนินการจะอ่านจากสมาชิกรอง
- replicaSet:’rs0′ – โดยค่าเริ่มต้นชื่อชุดการจำลองคือ rs0 ใน Ruk-Com คุณอาจสังเกตชื่อชุดการจำลองที่ cluster node ในไฟล์ mongod.conf หรือใน mongo shell prompt
การเชื่อมต่อแอปพลิเคชันที่ระบุไว้ข้างต้นถือเป็นการสร้างขึ้นภายในแพลตฟอร์ม one hosting แต่ถ้าจำเป็นคุณสามารถเชื่อมต่อแอปพลิเคชันภายนอกกับแบบจำลองที่ตั้งค่าผ่าน SLB ได้ ในกรณีนี้คุณต้องรักษาการเชื่อมต่อกับโหนดหลักสำหรับการอ่าน / เขียนผ่าน link # Ruk-Com Endpoints เท่านั้น

หากคุณต้องการอ่านจากลำดับที่สองคุณต้องปรับแต่งโค้ดแอปพลิเคชันของคุณเพื่อทำการอ่านจากลำดับที่สองในเธรดแยกเช่นเดียวกับที่คุณทำสำหรับไฟล์หลัก อย่างไรก็ตามสำหรับกรณีดังกล่าวคุณต้องลบพารามิเตอร์ replicaSet ออกจากสตริงการเชื่อมต่อ สามารถดูได้ตามอีเมลด้านบน:
client = new MongoClient(
"mongodb://admin:[email protected]:11035/admin",
{ useUnifiedTopology: true }
);4. โดยค่าเริ่มต้น auto-cluster จะใช้พาเนลแอดมิน Mongo Express มีมาให้กับแพคเกจ
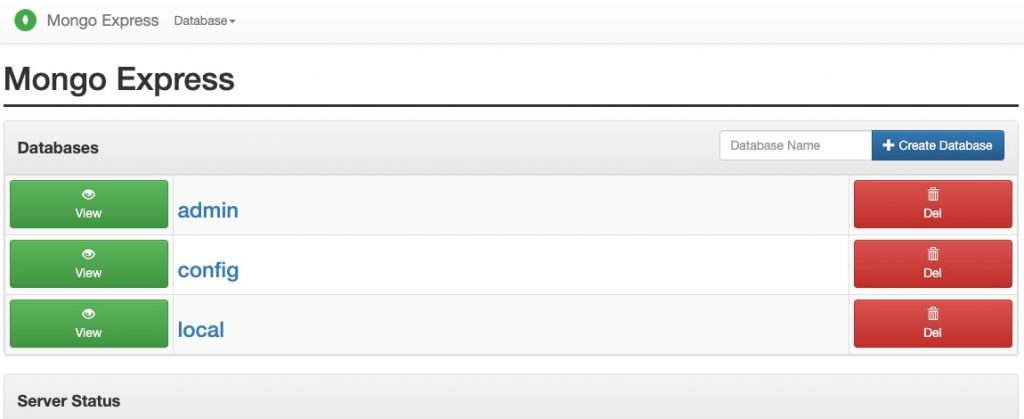
5. นอกจากนี้คุณสามารถเชื่อมต่อกับฐานข้อมูลของคุณผ่าน mongo shell ได้โดยตรงในเทอร์มินัลของคุณ (ตัวอย่างเช่นการใช้ตัวเลือก Web SSH แบบบิวท์อิน)
mongo -u {user} -p {password} {DB_name}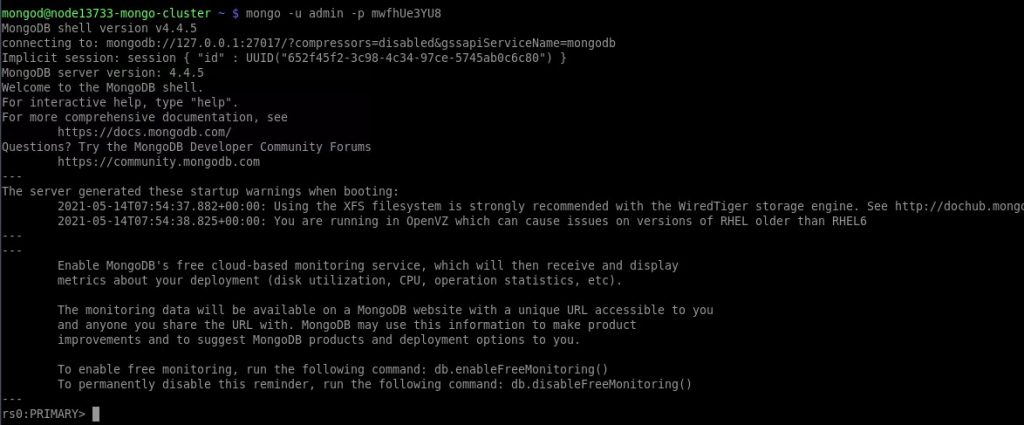
โดยที่ :
- {user} – ชื่อผู้ใช้ของผู้ดูแลระบบ (ส่งไปยังอีเมลของคุณโดยค่าเริ่มต้นคือ admin)
- {password} – รหัสผ่านสำหรับผู้ใช้ฐานข้อมูลที่เกี่ยวข้อง (สามารถพบได้ในอีเมลเดียวกัน)
- {DB_name} – ชื่อฐานข้อมูลที่คุณต้องการเข้าถึง (เราจะใช้ admin เป็นค่าเริ่มต้น)
6. คุณสามารถตรวจสอบสถานะชุดการจำลองด้วยคำสั่งที่เหมาะสม:
rs.status()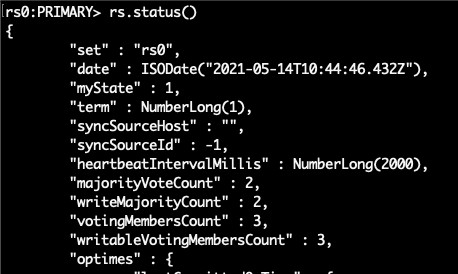
อย่างที่คุณเห็นชุดการจำลอง (ที่มีชื่อ rs0 เป็นค่าเริ่มต้น) พร้อมใช้งานแล้ว สามารถดู replica set commands อื่น ๆ ได้ที่เอกสารของออฟฟิเชียล ตัวอย่างเช่นใช้การดำเนินการ rs.conf() หากคุณต้องการดูการกำหนดค่าชุดการจำลอง
รับชุด MongoDB replica ที่มีความพร้อมใช้งานสูงของคุณเองด้วย Ruk-Com Cloud

